
Witaj w fascynującym świecie uczenia maszynowego (ML)! Kiedy myślisz, że maszyny przejmują kontrolę, masz rację, ale w dobrym sensie. Ta technologia pozwala komputerom uczyć się na podstawie danych. Dzięki temu komputery stają się coraz mądrzejsze, prawie jak my po kilku filiżankach kawy! Zanim jednak zanurzymy się w ten algorytmiczny ocean, warto poznać podstawowe terminy. Otworzą one przed nami drzwi do tej technologicznej przygody.
Na samym początku trzeba zrozumieć różnicę między modelami nadzorowanymi a nienadzorowanymi. Modele nadzorowane przypominają nauczycieli. Zadają one pytania z odpowiedziami w zestawie danych. Z drugiej strony modele nienadzorowane to samodzielni uczniowie. Muszą odkrywać wzory w danych bez pomocy. W skrócie, jedni uczą się z przykładów, a drudzy starają się zrozumieć świat na własną rękę. Zrobiliście już jakieś domowe zadanie? Bez tego nie stworzycie działającego modelu!
Nie możemy też zapominać o znaczeniu danych oraz ich przygotowania. Wyobraź sobie, że dane są składnikami w przepisie na ciasto. Muszą być świeże, dobrze dobrane, a czasami także odpowiednio posiekane. To pozwala uzyskać smaczny końcowy efekt. Każdy kawałek danych ma swoje znaczenie. Usunięcie szumów czy wypełnienie braków to kluczowe zadanie. To zwiększa szansę na sukces twojego modelu. Pamiętaj, wkładanie wysiłku w jakość danych to must-have w Moim Kuchni Uczenia Maszynowego!
Oto kilka kluczowych kroków przygotowania danych:
- Usunięcie szumów z danych.
- Wypełnienie braków w zbiorze danych.
- Normalizacja i skalowanie danych.
- Selekcja odpowiednich cech do analizy.
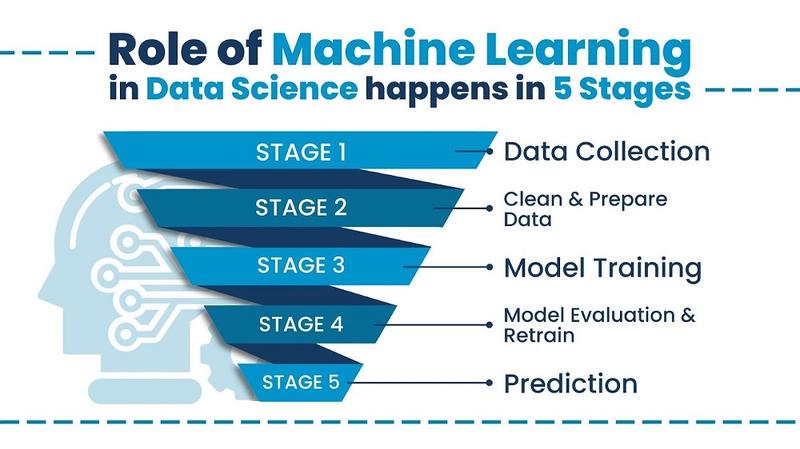
Gdy już mamy czyste i dobrze przygotowane dane, czas na akcję! Budowanie modelu przypomina składanie mebli z IKEA. To może być skomplikowane, ale satysfakcja jest ogromna. Musimy dostosować wielkość i formę, wybierając odpowiednie algorytmy do danych. Pojawia się tutaj cała gama opcji: regresja, drzewa decyzyjne, czy sieci neuronowe. Każdy model ma swoją osobowość. Wybierz ten, który najlepiej pasuje do twoich potrzeb. Pamiętaj, model ma uczyć się na twoich daniach, a nie odwrotnie!
Najpopularniejsze Algorytmy: Jak Wybrać Odpowiednią Metodę dla Swojego Projektu?
W świecie algorytmów uczenia maszynowego wybór odpowiedniego algorytmu dla projektu ma kluczowe znaczenie. To przypomina wybór najlepszego pieprzu do potrawy. Musisz jednak dobrze znać dostępne składniki, zanim rozpoczniesz gotowanie. Na szczęście dysponujemy różnymi technikami, które możemy dostosować do swoich potrzeb. Najpopularniejsze algorytmy obejmują regresję liniową, drzewa decyzyjne oraz nowoczesne sieci neuronowe. Te ostatnie potrafią niemal wszystko, od grania w szachy po rozpoznawanie kotów na zdjęciach. Wybór algorytmu powinien opierać się na rodzaju problemu i typie danych, które posiadasz.
Ale zanim wsiądziesz w tę przygodę z algorytmami, pamiętaj o przygotowaniu danych. To podobne do przyrządzenia składników przed gotowaniem. Bez odpowiedniego przetworzenia danych model może okazać się bezużyteczny. Może sprawić, że będziemy mieli do czynienia z czymś nieprzyjemnym. Dlatego upewnij się, że dane są czyste i dobrze zorganizowane. Następnie rozważ, jakie cechy danych będą kluczowe dla twojego modelu. Pomyśl także, jakich cech lepiej unikać, aby nie skomplikować sytuacji.

Po odpowiednim przygotowaniu danych możemy przejść do budowy modelu. Wybór architektury modelu przypomina wybór formy na ciasto. Forma musi pasować do oczekiwanego rezultatu. Dla prostych problemów wystarczy model regresyjny. Jednak dla bardziej skomplikowanych spraw, np. analizy obrazów, potrzebujemy zaawansowanych sieci neuronowych. Przypomnij sobie, że hiperparametry to przyprawy w tym procesie. Małe zmiany mogą wpłynąć na końcowy smak potrawy. Po dostosowaniu modelu sprawdź, jak się sprawuje na zestawie testowym. Wtedy będziesz mógł ocenić, czy twoje danie zasługuje na nagrodę kulinarną.
Poniżej przedstawiamy kilka kluczowych aspektów, które warto wziąć pod uwagę przy wyborze algorytmu:
- Rodzaj problemu do rozwiązania (regresja, klasyfikacja, klasteryzacja).
- Rodzaj danych (numeryczne, kategoryczne, obrazowe).
- Wymagana złożoność modelu.
- Dostępność zasobów obliczeniowych.
- Wymagana interpretowalność modelu.
| Aspekt | Opis |
|---|---|
| Rodzaj problemu | Do rozwiązania: regresja, klasyfikacja, klasteryzacja. |
| Rodzaj danych | Numeryczne, kategoryczne, obrazowe. |
| Złożoność modelu | Wymagana złożoność modelu w zależności od problemu. |
| Zasoby obliczeniowe | Dostępność zasobów obliczeniowych do trenowania modelu. |
| Interpretowalność modelu | Wymagana interpretowalność modelu w kontekście zastosowania. |
Praktyczne Przykłady: Budowanie Modelu Krok po Kroku
Budowanie modelu uczenia maszynowego przypomina tworzenie skomplikowanego zamku z klocków. Początkowo wydaje się proste, ale wystarczy jeden zły klocek. Wybieramy algorytm, co można porównać do fundamentów. Na przykład, budując zamek dla księżniczki (klasyfikacja), stosujemy inne podejście niż dla rycerza (regresja). Dobre algorytmy, jak drzewa decyzyjne lub regresja liniowa, pomogą dobrać odpowiedni środek do rozwiązania problemu.
Kiedy wybierzemy algorytm, przystępujemy do przygotowania danych. Ten etap przypomina wielkie sprzątanie przed imprezą. Sprawdzamy, czy mamy zbyt dużo szumu, brakujące wartości, lub outliery. W takiej sytuacji uzupełniamy, usuwamy albo maskujemy niepasujące elementy. Dzięki temu nasz model zyska szansę na świetne wyniki. Normalizacja i eliminacja mogą okazać się niezwykle pomocne!
Budowa i konfiguracja modelu to następny krok. Przy tym dobieramy architekturę, jak meble do nowego mieszkania. Kto chciałby żyć w zamku z minimalistycznym stylem z lat siedemdziesiątych? Dobór hiperparametrów jest kluczowy – jak wybór długości nóg do stołka. Następnie przyszedł czas na trening. Bez tego model nie stanie się ekspertem w przewidywaniu. Pamiętajmy o unikaniu przeuczenia! Mamy świetne sztuczki, jak regularizacja czy early stopping.
- Regularizacja – technika zmniejszająca przeuczenie modelu.
- Early stopping – zatrzymanie treningu, gdy wydajność modelu przestaje poprawiać się na danych walidacyjnych.
- Wybór architektury – ważny aspekt, który wpływa na efektywność modelu.
Ostatni etap to testowanie modelu. Sprawdzamy, czy nasz model działa w rzeczywistości. Chcemy uniknąć sytuacji, gdzie przewidujemy wiosnę, gdy za oknem leży śnieg. Monitorując model po wdrożeniu, możemy szybko rozwiązywać problemy. Tak dochodzimy do sukcesu! W świecie uczenia maszynowego, krok po kroku budując, trenując i weryfikując nasze modele, osiągniemy niesamowite rezultaty. A kto wie, może zbudujemy królestwo danych!
Wyzwania i Pułapki w Procesie Treningu: Czego Unikać?
Trening modeli uczenia maszynowego to nie tylko skomplikowane równania i algorytmy, ale także długi maraton. W tym przedsięwzięciu strategia i podejście do projektu odgrywają kluczową rolę. Często jednak entuzjazm początkujących programistów oraz data scientistów wpada w pułapki. Te pułapki związane są z wyborami technologicznymi, brakiem danych oraz chaotycznym zarządzaniem projektem. Właśnie dlatego warto znać kilka zasadniczych zasad, które pomagają uniknąć niepożądanych problemów.
Na początek pamiętaj, że nie każda metoda pasuje do każdego problemu. Choć kuszące, aby skoczyć w wir programowania, lepiej jest zaplanować to wcześniej. Wybór algorytmu zbyt szybko może prowadzić do rozczarowań. Decyzje powinny opierać się na charakterystyce danych. Zanim wybierzemy sieć neuronową, sprawdźmy, czy nie wystarczy bardziej „tradycyjny” algorytm, jak regresja lub drzewa decyzyjne. Szukanie odpowiedzi na pytania typu „dlaczego mój model nie działa?” jest prostsze po sprawdzeniu używanych narzędzi.
Następnym krokiem jest przygotowanie danych. Ciągłe zapominanie o jakości danych to powszechny błąd. Można to porównać do pieczenia ciastka z zapałkami zamiast z mąki. Zanim zaczniesz trening, upewnij się, że dane są czyste, kompletne i odpowiednio przetworzone. Pewnie zdarzyło się każdemu spędzać godziny na treningu modelu. W końcu odkrywają, że dane zawierały luki lub błędy, co prowadzi do frustracji!

Ostatnia, ale równie ważna kwestia to ewaluacja modelu. Nie daj się zwieść jednorazowym sukcesem w warunkach idealnych. Stwórz odpowiednie metryki oceny i testuj model na różnych zestawach danych. Upewnij się, że model działa w rzeczywistości. Nie wystarczy wrzucić wytrawnej aplikacji „czaru”, aby stała się idealnym rozwiązaniem dla realnych użytkowników. Dlatego zawsze miej na uwadze, że w procesie treningu kluczowe są przemyślane wybory, dbałość o jakość oraz ciągła ewaluacja! W końcu, jak mówi mądrość ludowa – lepiej zapobiegać niż leczyć!
Poniżej znajdują się kluczowe zasady, które warto przestrzegać w procesie treningu modeli:
- Dokładna analiza potrzeb związanych z danymi.
- Staranny wybór algorytmu na podstawie charakterystyki danych.
- Utrzymywanie wysokiej jakości danych, eliminacja luk i błędów.
- Systematyczna ewaluacja modelu i testowanie na różnych zestawach danych.








{kind=link}